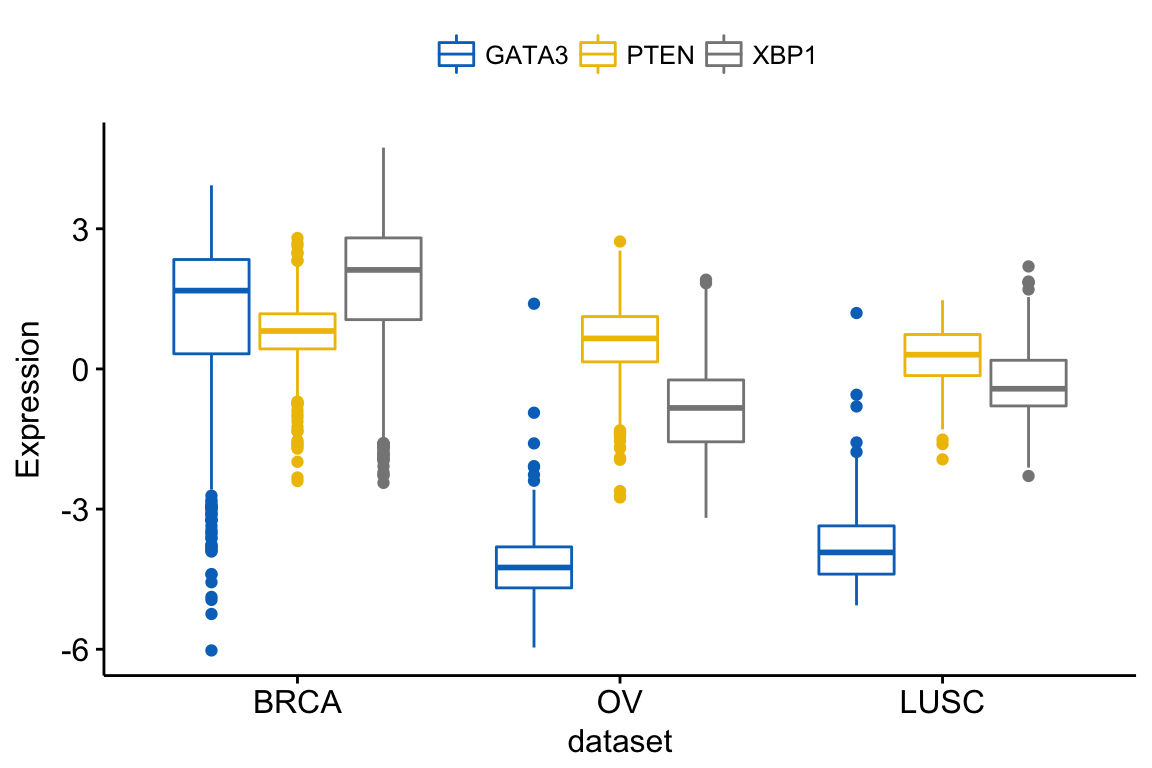
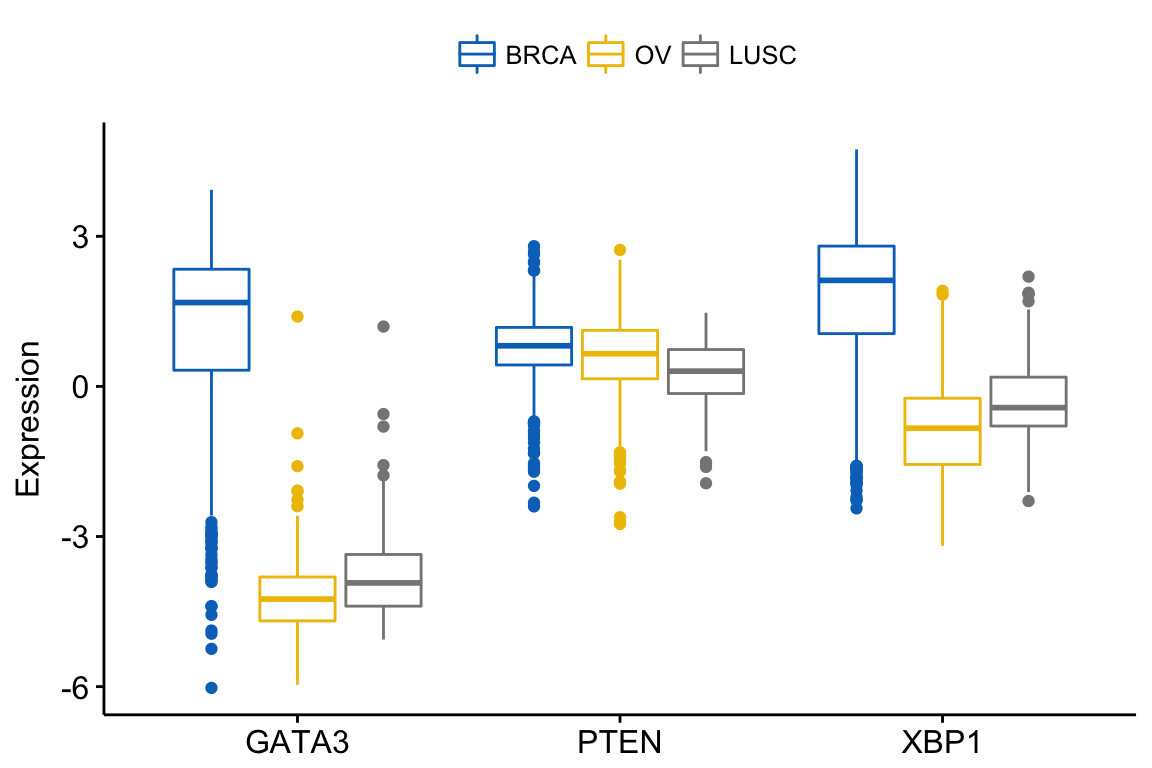
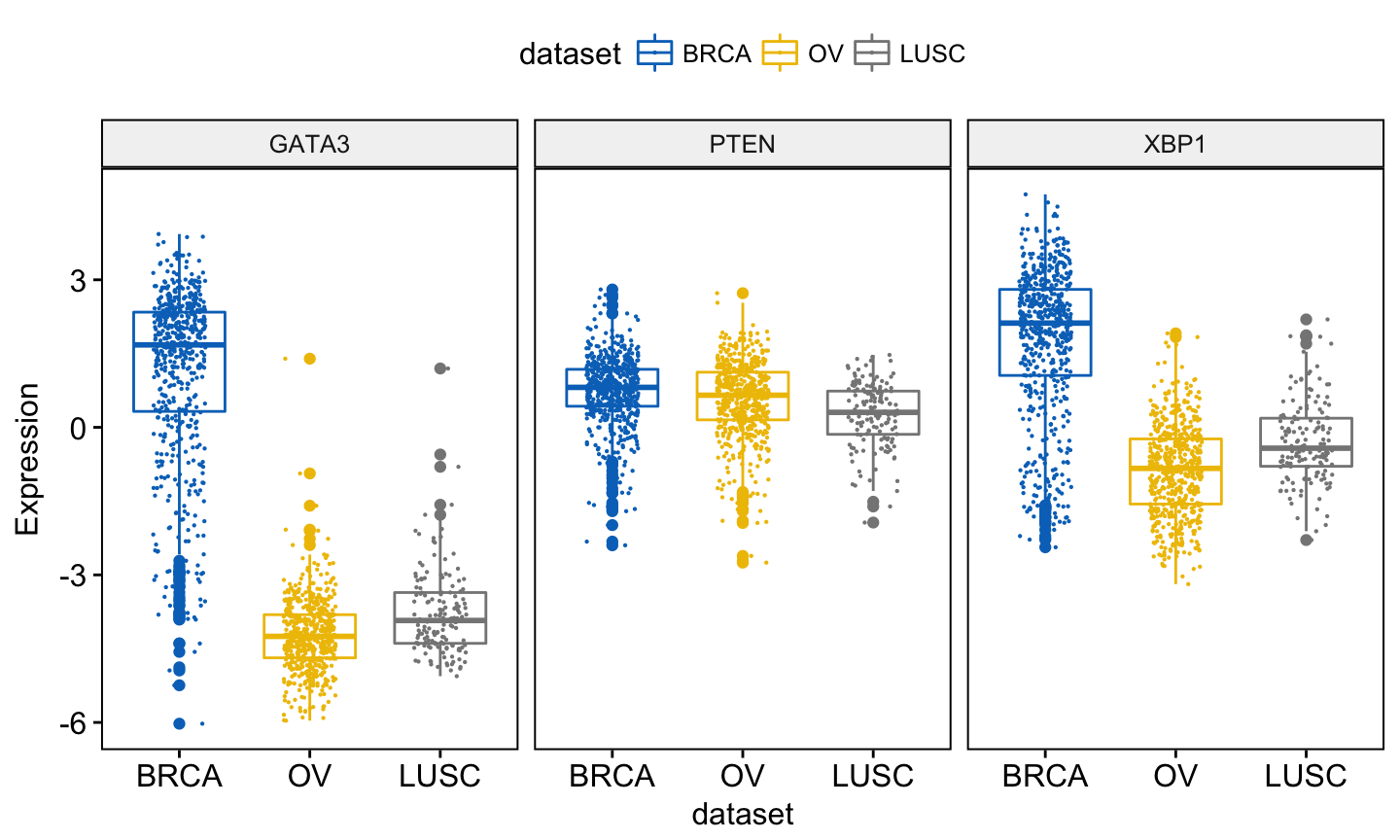
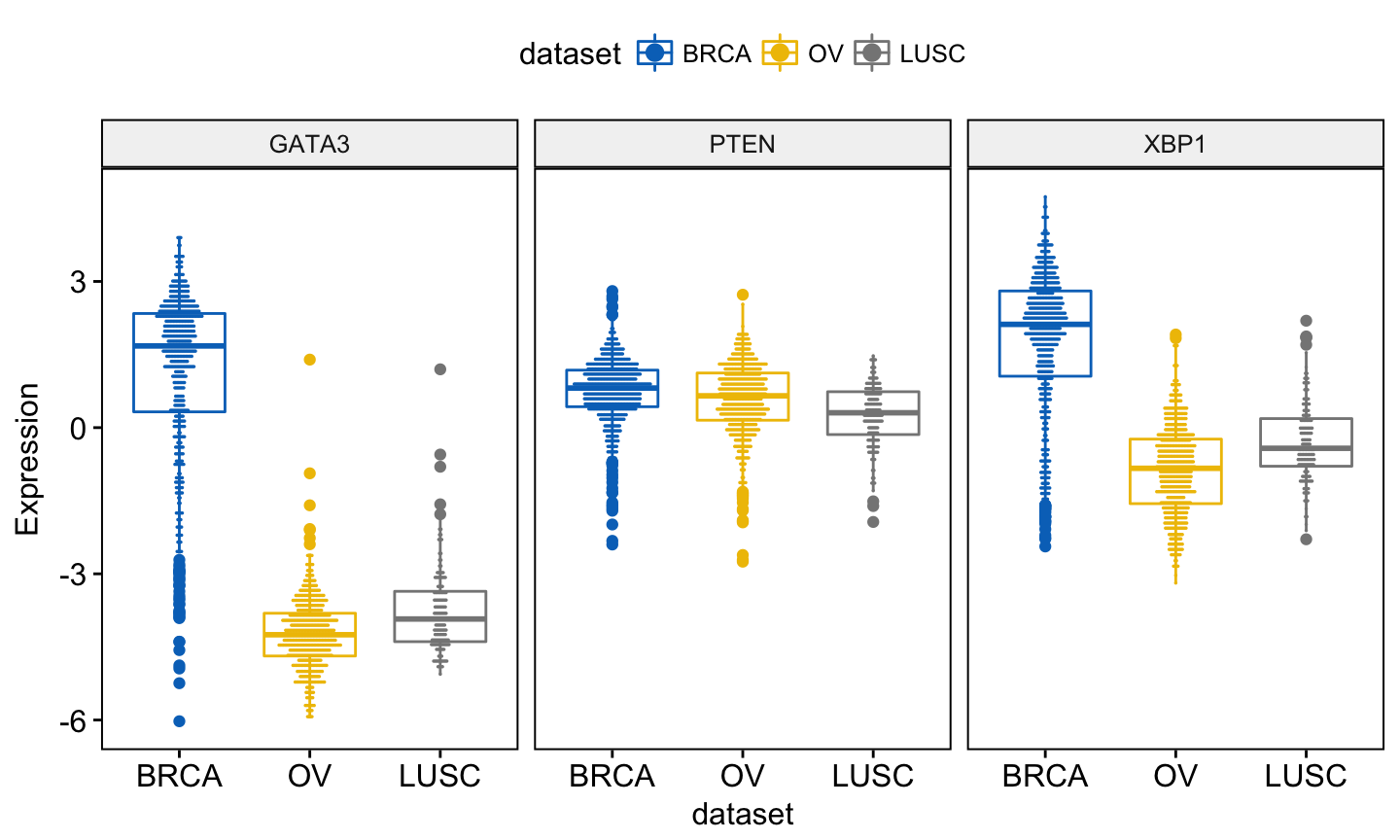
In this article, we’ll describe how to easily i) compare means of two or multiple groups; ii) and to automatically add p-values and significance levels to a ggplot (such as box plots, dot plots, bar plots and line plots …).
Contents:
Prerequisites
Install and load required R packages
Required R package: ggpubr (version >= 0.1.3), for ggplot2-based publication ready plots.
- Install from CRAN as follow:
install.packages("ggpubr")- Or, install the latest developmental version from GitHub as follow:
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/ggpubr")- Load ggpubr:
library(ggpubr)Official documentation of ggpubr is available at: http://www.sthda.com/english/rpkgs/ggpubr
Demo data sets
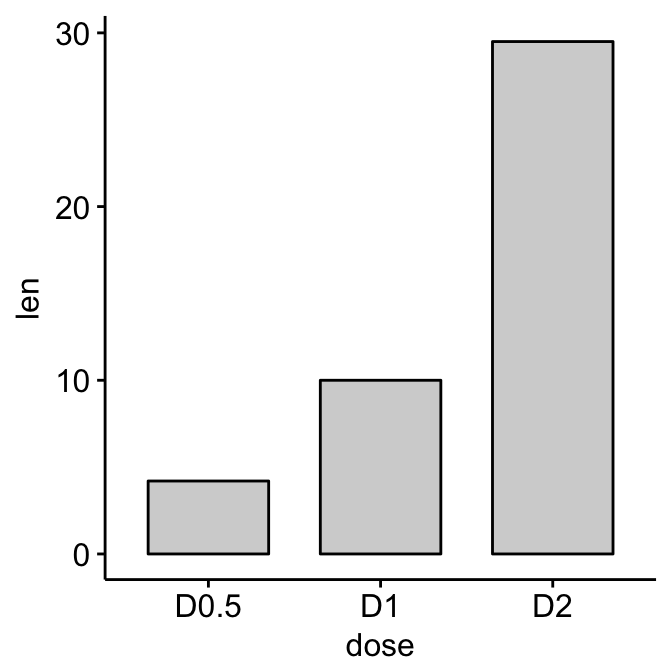
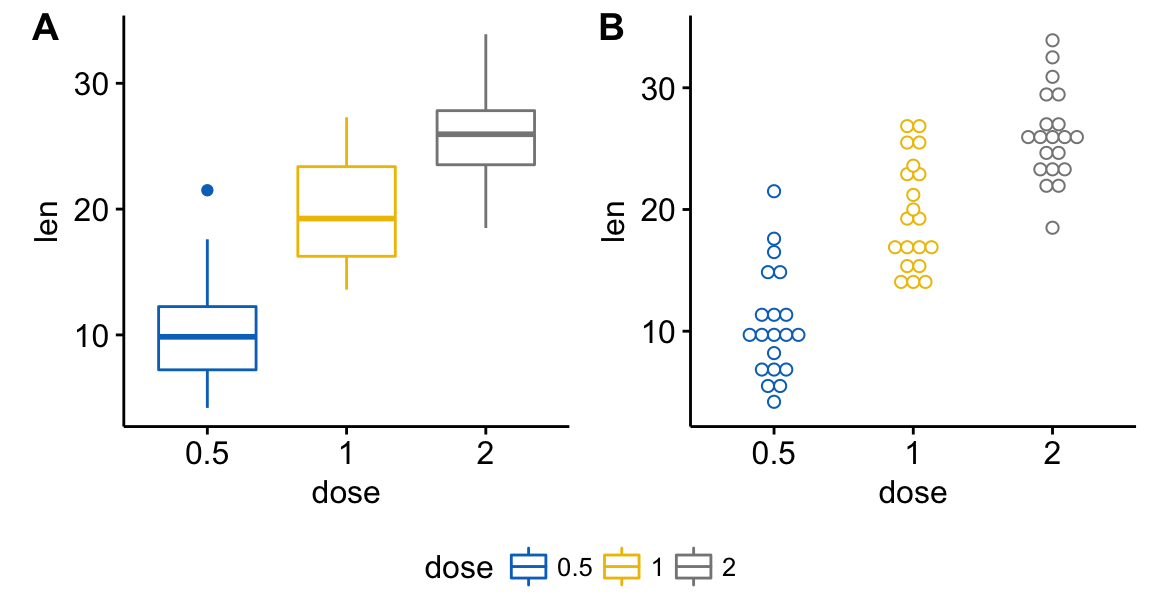
Data: ToothGrowth data sets.
data("ToothGrowth")
head(ToothGrowth) len supp dose
1 4.2 VC 0.5
2 11.5 VC 0.5
3 7.3 VC 0.5
4 5.8 VC 0.5
5 6.4 VC 0.5
6 10.0 VC 0.5Methods for comparing means
The standard methods to compare the means of two or more groups in R, have been largely described at: comparing means in R.
The most common methods for comparing means include:
| Methods | R function | Description |
|---|---|---|
| T-test | t.test() | Compare two groups (parametric) |
| Wilcoxon test | wilcox.test() | Compare two groups (non-parametric) |
| ANOVA | aov() or anova() | Compare multiple groups (parametric) |
| Kruskal-Wallis | kruskal.test() | Compare multiple groups (non-parametric) |
A practical guide to compute and interpret the results of each of these methods are provided at the following links:
- Comparing one-sample mean to a standard known mean:
- Comparing the means of two independent groups:
- Comparing the means of paired samples:
-
Comparing the means of more than two groups
- Analysis of variance (ANOVA, parametric):
- Kruskal-Wallis Test in R (non parametric alternative to one-way ANOVA)
R functions to add p-values
Here we present two new R functions in the ggpubr package:
- compare_means(): easy to use solution to performs one and multiple mean comparisons.
- stat_compare_means(): easy to use solution to automatically add p-values and significance levels to a ggplot.
compare_means()
As we’ll show in the next sections, it has multiple useful options compared to the standard R functions.
The simplified format is as follow:
compare_means(formula, data, method = "wilcox.test", paired = FALSE,
group.by = NULL, ref.group = NULL, ...)- formula: a formula of the form x ~ group, where x is a numeric variable and group is a factor with one or multiple levels. For example, formula = TP53 ~ cancer_group. It’s also possible to perform the test for multiple response variables at the same time. For example, formula = c(TP53, PTEN) ~ cancer_group.
data: a data.frame containing the variables in the formula.
- method: the type of test. Default is “wilcox.test”. Allowed values include:
- “t.test” (parametric) and “wilcox.test”" (non-parametric). Perform comparison between two groups of samples. If the grouping variable contains more than two levels, then a pairwise comparison is performed.
- “anova” (parametric) and “kruskal.test” (non-parametric). Perform one-way ANOVA test comparing multiple groups.
paired: a logical indicating whether you want a paired test. Used only in t.test and in wilcox.test.
group.by: variables used to group the data set before applying the test. When specified the mean comparisons will be performed in each subset of the data formed by the different levels of the group.by variables.
ref.group: a character string specifying the reference group. If specified, for a given grouping variable, each of the group levels will be compared to the reference group (i.e. control group). ref.group can be also “.all.”. In this case, each of the grouping variable levels is compared to all (i.e. base-mean).
stat_compare_means()
This function extends ggplot2 for adding mean comparison p-values to a ggplot, such as box blots, dot plots, bar plots and line plots.
The simplified format is as follow:
stat_compare_means(mapping = NULL, comparisons = NULL hide.ns = FALSE,
label = NULL, label.x = NULL, label.y = NULL, ...)mapping: Set of aesthetic mappings created by aes().
comparisons: A list of length-2 vectors. The entries in the vector are either the names of 2 values on the x-axis or the 2 integers that correspond to the index of the groups of interest, to be compared.
hide.ns: logical value. If TRUE, hide ns symbol when displaying significance levels.
label: character string specifying label type. Allowed values include “p.signif” (shows the significance levels), “p.format” (shows the formatted p value).
label.x,label.y: numeric values. coordinates (in data units) to be used for absolute positioning of the label. If too short they will be recycled.
…: other arguments passed to the function compare_means() such as method, paired, ref.group.
Compare two independent groups
Perform the test:
compare_means(len ~ supp, data = ToothGrowth)# A tibble: 1 x 8
.y. group1 group2 p p.adj p.format p.signif method
1 len OJ VC 0.06449067 0.06449067 0.064 ns Wilcoxon By default method = “wilcox.test” (non-parametric test). You can also specify method = “t.test” for a parametric t-test.
Returned value is a data frame with the following columns:
- .y.: the y variable used in the test.
- p: the p-value
- p.adj: the adjusted p-value. Default value for p.adjust.method = “holm”
- p.format: the formatted p-value
- p.signif: the significance level.
- method: the statistical test used to compare groups.
Create a box plot with p-values:
p <- ggboxplot(ToothGrowth, x = "supp", y = "len",
color = "supp", palette = "jco",
add = "jitter")
# Add p-value
p + stat_compare_means()
# Change method
p + stat_compare_means(method = "t.test")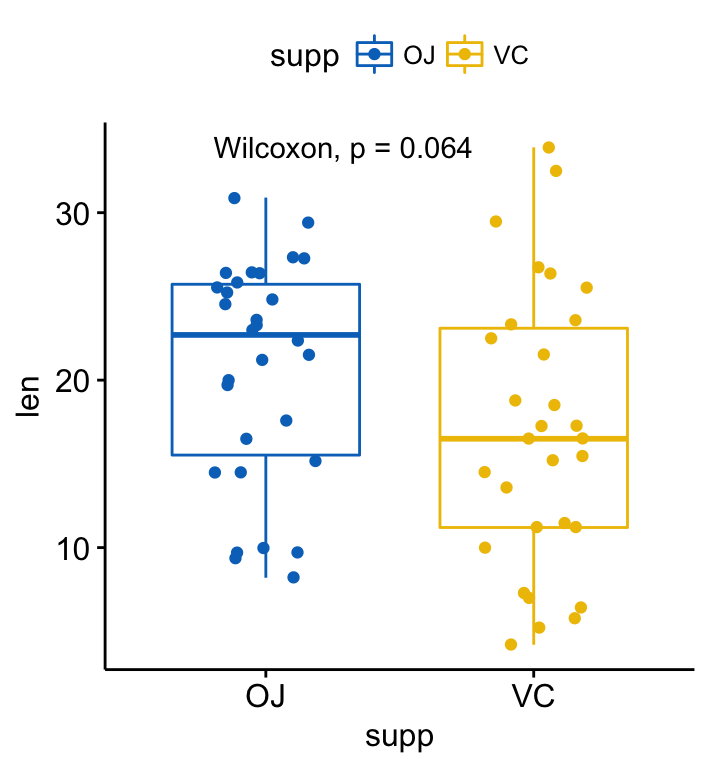
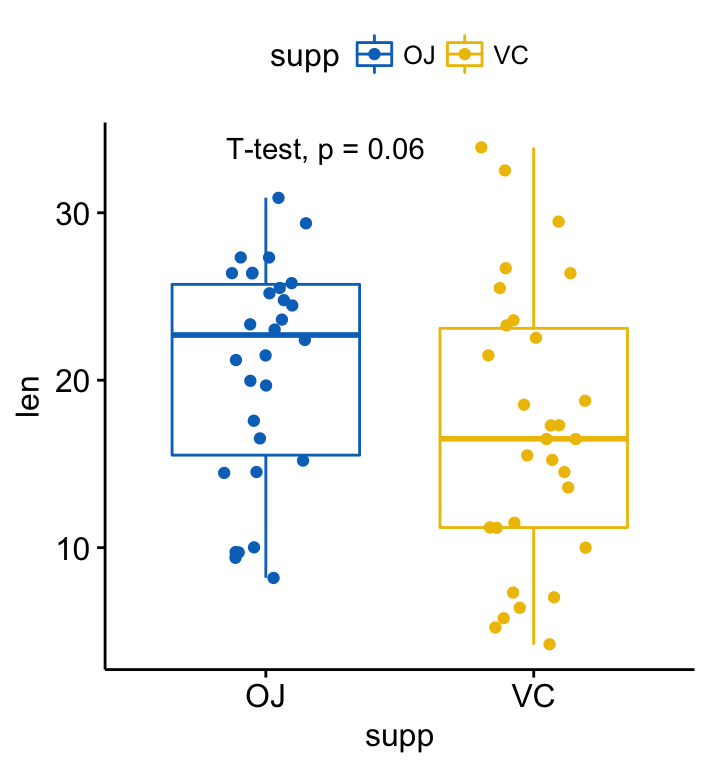
Add p-values and significance levels to ggplots
Note that, the p-value label position can be adjusted using the arguments: label.x, label.y, hjust and vjust.
The default p-value label displayed is obtained by concatenating the method and the p columns of the returned data frame by the function compare_means(). You can specify other combinations using the aes() function.
For example,
- aes(label = ..p.format..) or aes(label = paste0(“p =”, ..p.format..)): display only the formatted p-value (without the method name)
- aes(label = ..p.signif..): display only the significance level.
- aes(label = paste0(..method.., “\n”, “p =”, ..p.format..)): Use line break (“\n”) between the method name and the p-value.
As an illustration, type this:
p + stat_compare_means( aes(label = ..p.signif..),
label.x = 1.5, label.y = 40)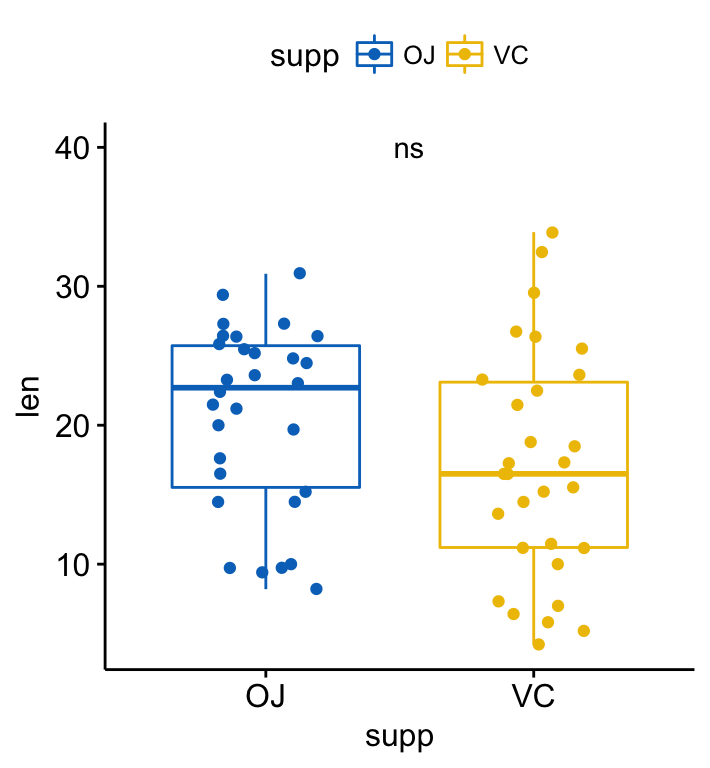
Add p-values and significance levels to ggplots
If you prefer, it’s also possible to specify the argument label as a character vector:
p + stat_compare_means( label = "p.signif", label.x = 1.5, label.y = 40)Compare two paired samples
Perform the test:
compare_means(len ~ supp, data = ToothGrowth, paired = TRUE)# A tibble: 1 x 8
.y. group1 group2 p p.adj p.format p.signif method
1 len OJ VC 0.004312554 0.004312554 0.0043 ** Wilcoxon Visualize paired data using the ggpaired() function:
ggpaired(ToothGrowth, x = "supp", y = "len",
color = "supp", line.color = "gray", line.size = 0.4,
palette = "jco")+
stat_compare_means(paired = TRUE)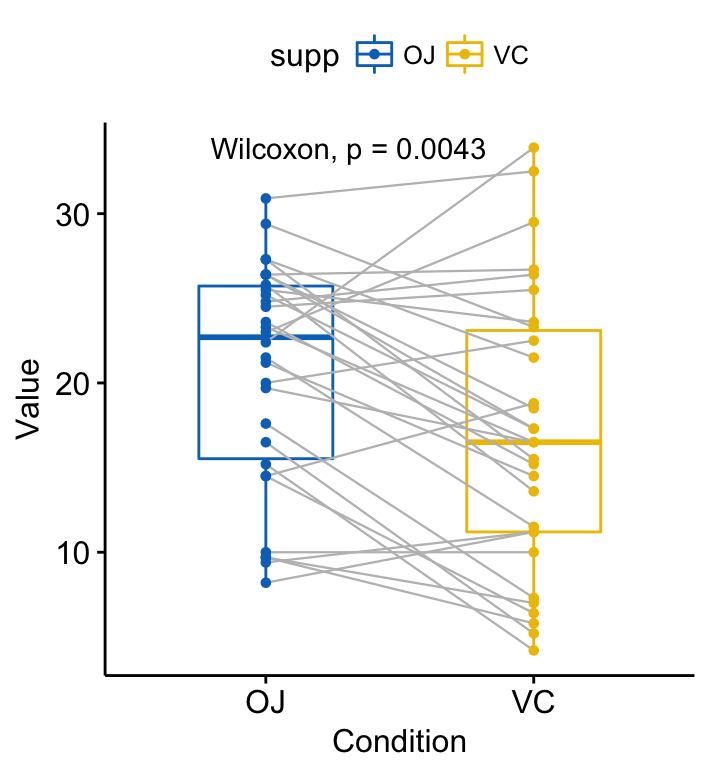
Add p-values and significance levels to ggplots
Compare more than two groups
- Global test:
# Global test
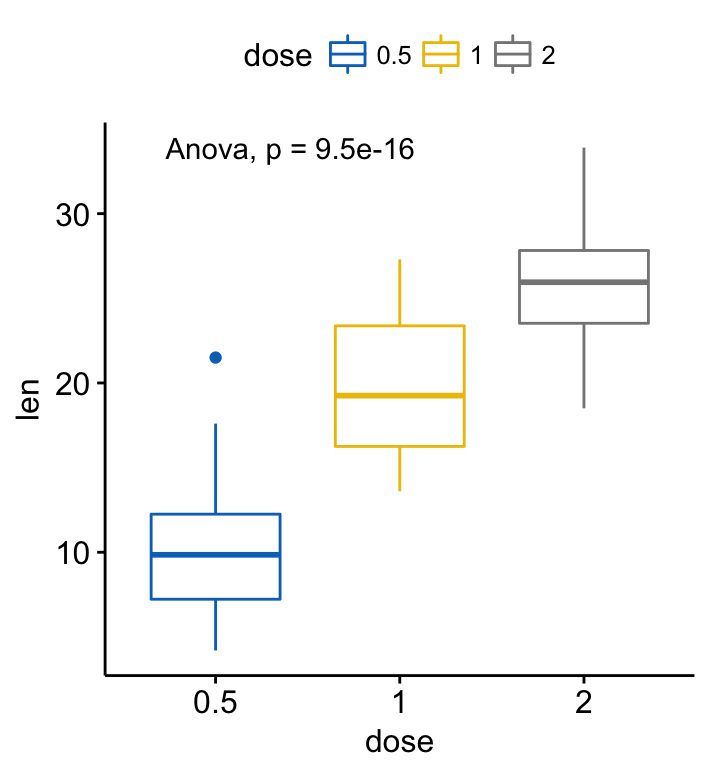
compare_means(len ~ dose, data = ToothGrowth, method = "anova")# A tibble: 1 x 6
.y. p p.adj p.format p.signif method
1 len 9.532727e-16 9.532727e-16 9.5e-16 **** Anova Plot with global p-value:
# Default method = "kruskal.test" for multiple groups
ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")+
stat_compare_means()
# Change method to anova
ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")+
stat_compare_means(method = "anova")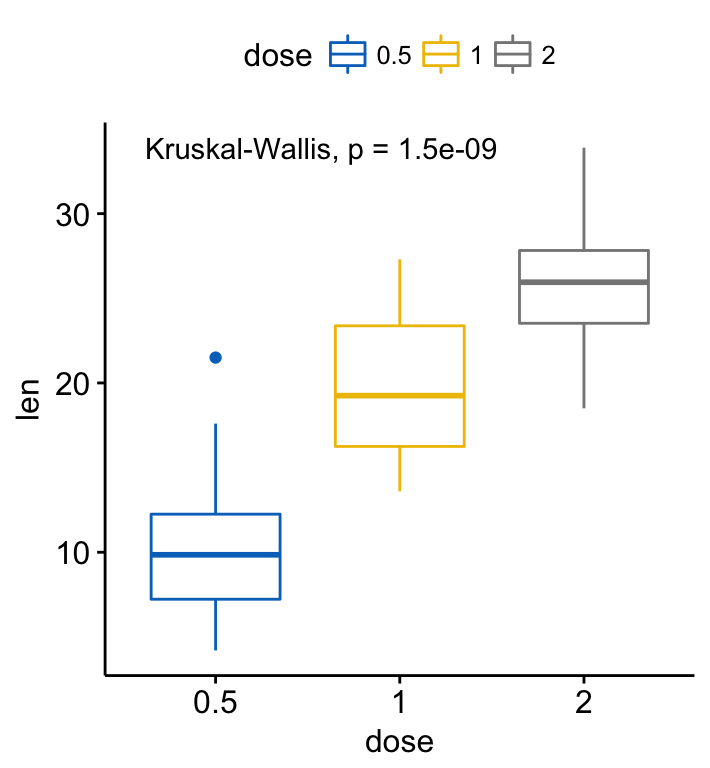
Add p-values and significance levels to ggplots
- Pairwise comparisons. If the grouping variable contains more than two levels, then pairwise tests will be performed automatically. The default method is “wilcox.test”. You can change this to “t.test”.
# Perorm pairwise comparisons
compare_means(len ~ dose, data = ToothGrowth)# A tibble: 3 x 8
.y. group1 group2 p p.adj p.format p.signif method
1 len 0.5 1 7.020855e-06 1.404171e-05 7.0e-06 **** Wilcoxon
2 len 0.5 2 8.406447e-08 2.521934e-07 8.4e-08 **** Wilcoxon
3 len 1 2 1.772382e-04 1.772382e-04 0.00018 *** Wilcoxon # Visualize: Specify the comparisons you want
my_comparisons <- list( c("0.5", "1"), c("1", "2"), c("0.5", "2") )
ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")+
stat_compare_means(comparisons = my_comparisons)+ # Add pairwise comparisons p-value
stat_compare_means(label.y = 50) # Add global p-value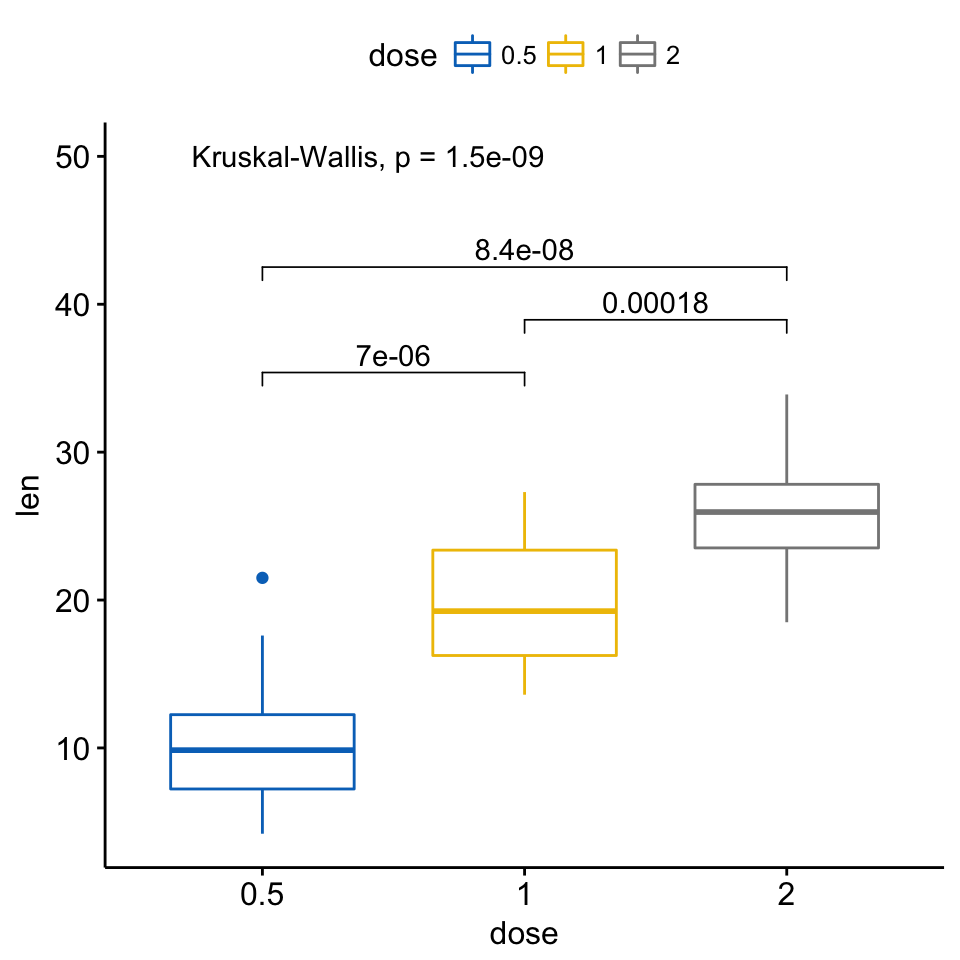
Add p-values and significance levels to ggplots
If you want to specify the precise y location of bars, use the argument label.y:
ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")+
stat_compare_means(comparisons = my_comparisons, label.y = c(29, 35, 40))+
stat_compare_means(label.y = 45)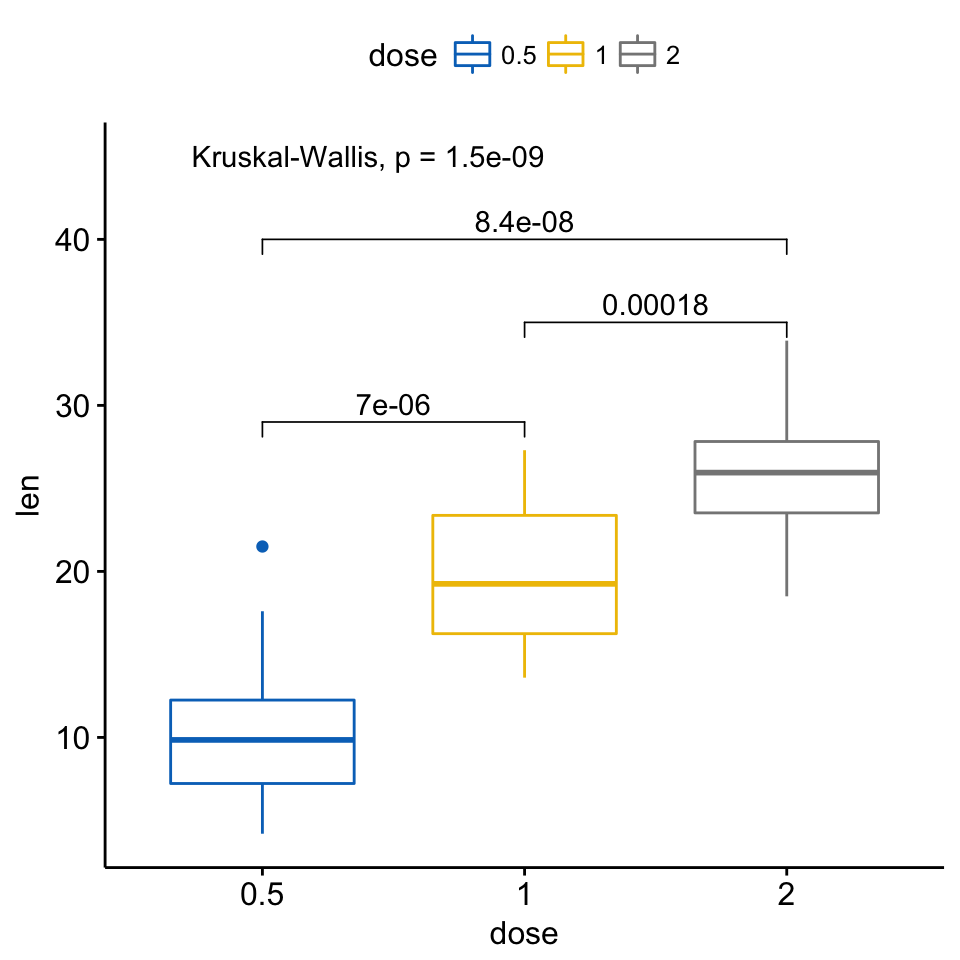
Add p-values and significance levels to ggplots
(Adding bars, connecting compared groups, has been facilitated by the ggsignif R package )
- Multiple pairwise tests against a reference group:
# Pairwise comparison against reference
compare_means(len ~ dose, data = ToothGrowth, ref.group = "0.5",
method = "t.test")# A tibble: 2 x 8
.y. group1 group2 p p.adj p.format p.signif method
1 len 0.5 1 6.697250e-09 6.697250e-09 6.7e-09 **** T-test
2 len 0.5 2 1.469534e-16 2.939068e-16 < 2e-16 **** T-test # Visualize
ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")+
stat_compare_means(method = "anova", label.y = 40)+ # Add global p-value
stat_compare_means(label = "p.signif", method = "t.test",
ref.group = "0.5") # Pairwise comparison against reference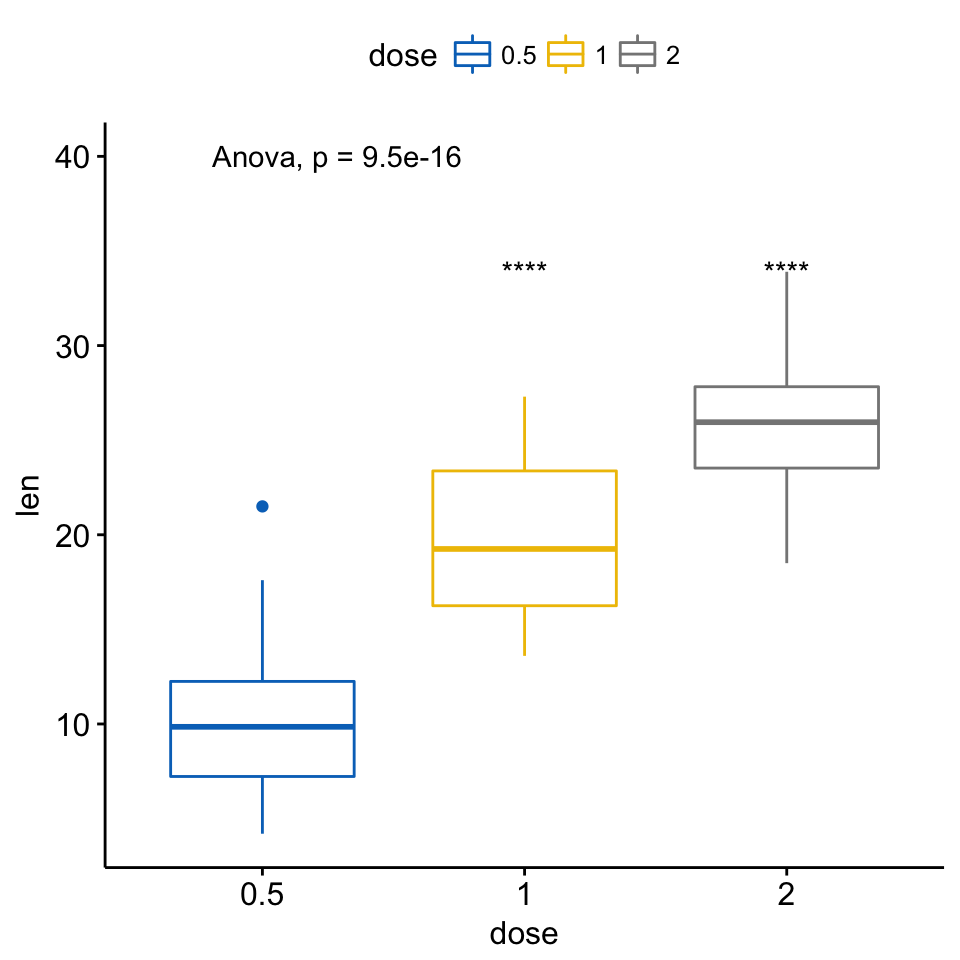
Add p-values and significance levels to ggplots
- Multiple pairwise tests against all (base-mean):
# Comparison of each group against base-mean
compare_means(len ~ dose, data = ToothGrowth, ref.group = ".all.",
method = "t.test")# A tibble: 3 x 8
.y. group1 group2 p p.adj p.format p.signif method
1 len .all. 0.5 1.244626e-06 3.733877e-06 1.2e-06 **** T-test
2 len .all. 1 5.667266e-01 5.667266e-01 0.57 ns T-test
3 len .all. 2 1.371704e-05 2.743408e-05 1.4e-05 **** T-test # Visualize
ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "dose", palette = "jco")+
stat_compare_means(method = "anova", label.y = 40)+ # Add global p-value
stat_compare_means(label = "p.signif", method = "t.test",
ref.group = ".all.") # Pairwise comparison against all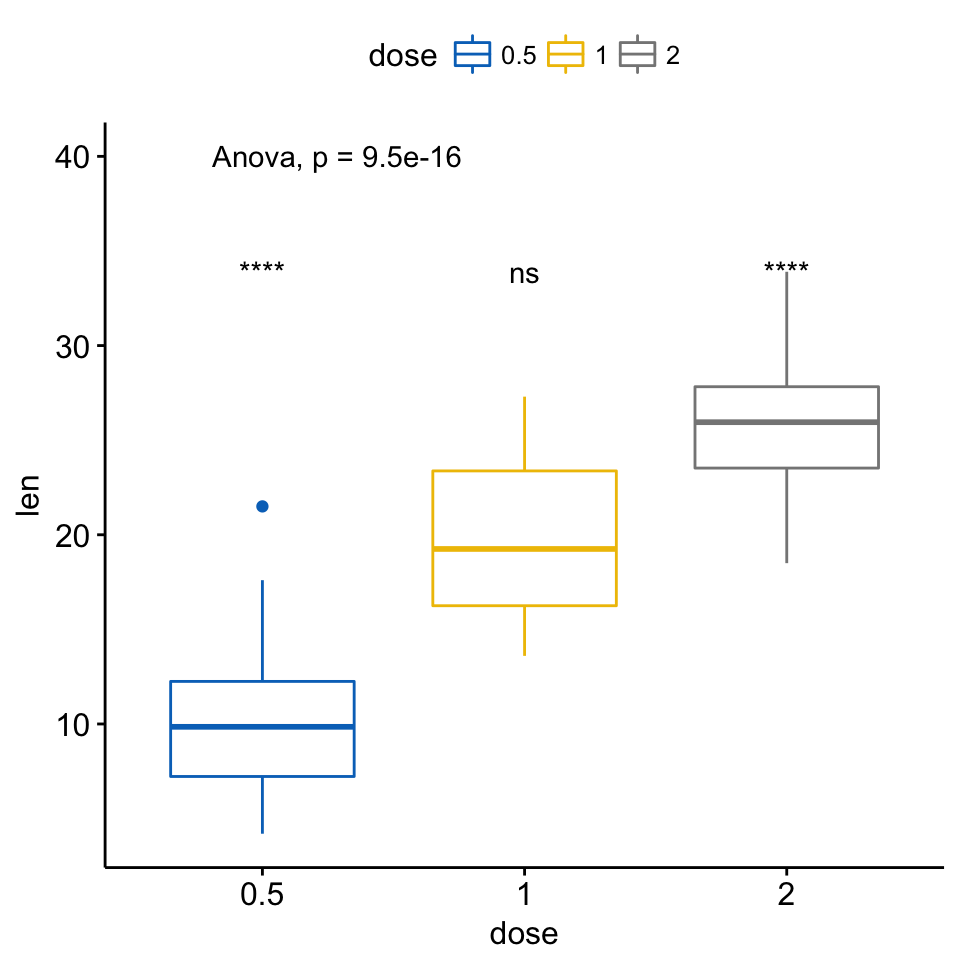
Add p-values and significance levels to ggplots
A typical situation, where pairwise comparisons against “all” can be useful, is illustrated here using the myeloma data set from the survminer package.
We’ll plot the expression profile of the DEPDC1 gene according to the patients’ molecular groups. We want to know if there is any difference between groups. If yes, where the difference is?
To answer to this question, you can perform a pairwise comparison between all the 7 groups. This will lead to a lot of comparisons between all possible combinations. If you have many groups, as here, it might be difficult to interpret.
Another easy solution is to compare each of the seven groups against “all” (i.e. base-mean). When the test is significant, then you can conclude that DEPDC1 is significantly overexpressed or downexpressed in a group xxx compared to all.
# Load myeloma data from survminer package
if(!require(survminer)) install.packages("survminer")
data("myeloma", package = "survminer")
# Perform the test
compare_means(DEPDC1 ~ molecular_group, data = myeloma,
ref.group = ".all.", method = "t.test")# A tibble: 7 x 8
.y. group1 group2 p p.adj p.format p.signif method
1 DEPDC1 .all. Cyclin D-1 1.496896e-01 4.490687e-01 0.14969 ns T-test
2 DEPDC1 .all. Cyclin D-2 5.231428e-01 1.000000e+00 0.52314 ns T-test
3 DEPDC1 .all. Hyperdiploid 2.815333e-04 1.689200e-03 0.00028 *** T-test
4 DEPDC1 .all. Low bone disease 5.083985e-03 2.541992e-02 0.00508 ** T-test
5 DEPDC1 .all. MAF 8.610664e-02 3.444265e-01 0.08611 ns T-test
6 DEPDC1 .all. MMSET 5.762908e-01 1.000000e+00 0.57629 ns T-test
7 DEPDC1 .all. Proliferation 1.241416e-09 8.689910e-09 1.2e-09 **** T-test # Visualize the expression profile
ggboxplot(myeloma, x = "molecular_group", y = "DEPDC1", color = "molecular_group",
add = "jitter", legend = "none") +
rotate_x_text(angle = 45)+
geom_hline(yintercept = mean(myeloma$DEPDC1), linetype = 2)+ # Add horizontal line at base mean
stat_compare_means(method = "anova", label.y = 1600)+ # Add global annova p-value
stat_compare_means(label = "p.signif", method = "t.test",
ref.group = ".all.") # Pairwise comparison against all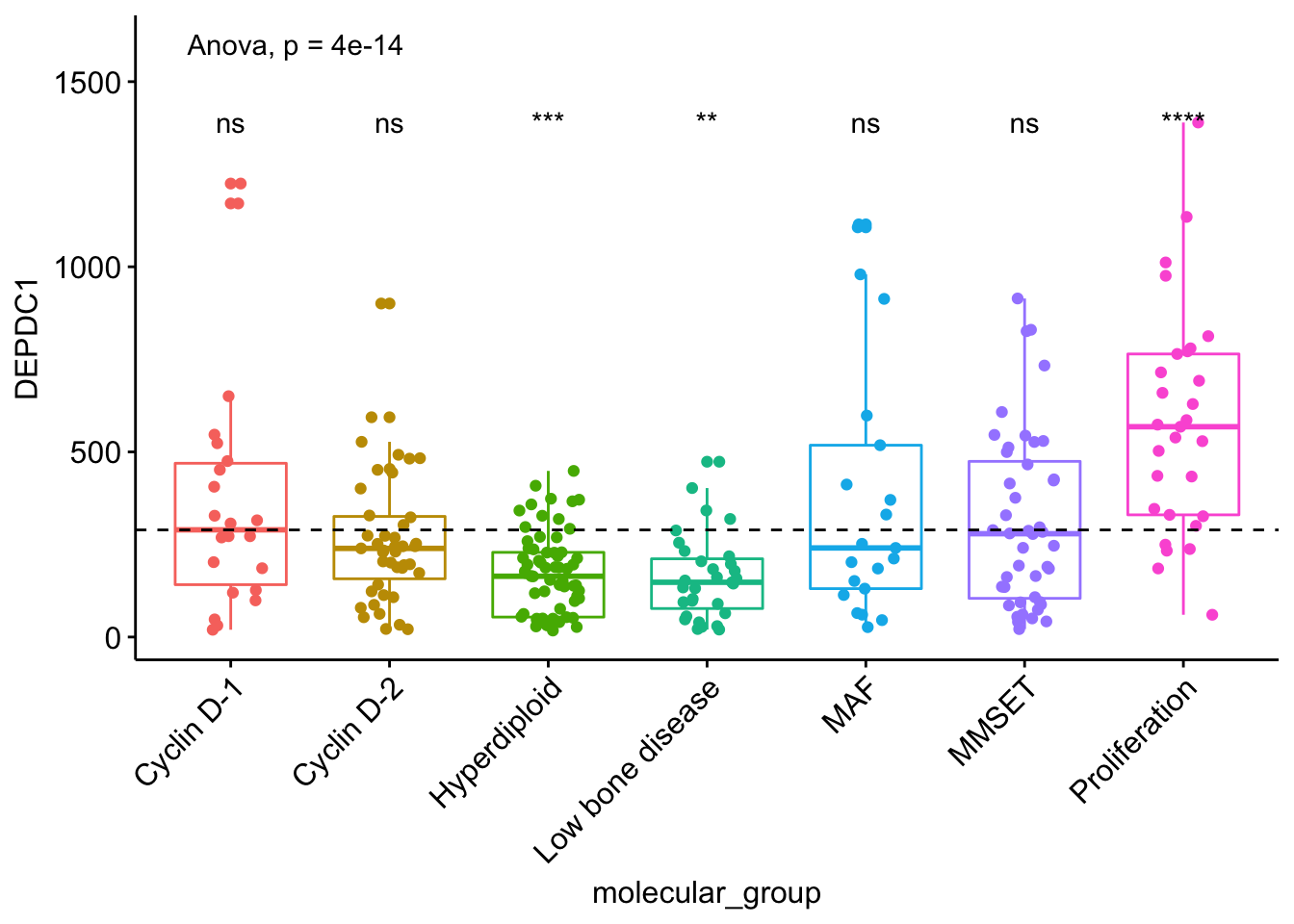
Add p-values and significance levels to ggplots
From the plot above, we can conclude that DEPDC1 is significantly overexpressed in proliferation group and, it’s significantly downexpressed in Hyperdiploid and Low bone disease compared to all.
Note that, if you want to hide the ns symbol, specify the argument hide.ns = TRUE.
# Visualize the expression profile
ggboxplot(myeloma, x = "molecular_group", y = "DEPDC1", color = "molecular_group",
add = "jitter", legend = "none") +
rotate_x_text(angle = 45)+
geom_hline(yintercept = mean(myeloma$DEPDC1), linetype = 2)+ # Add horizontal line at base mean
stat_compare_means(method = "anova", label.y = 1600)+ # Add global annova p-value
stat_compare_means(label = "p.signif", method = "t.test",
ref.group = ".all.", hide.ns = TRUE) # Pairwise comparison against all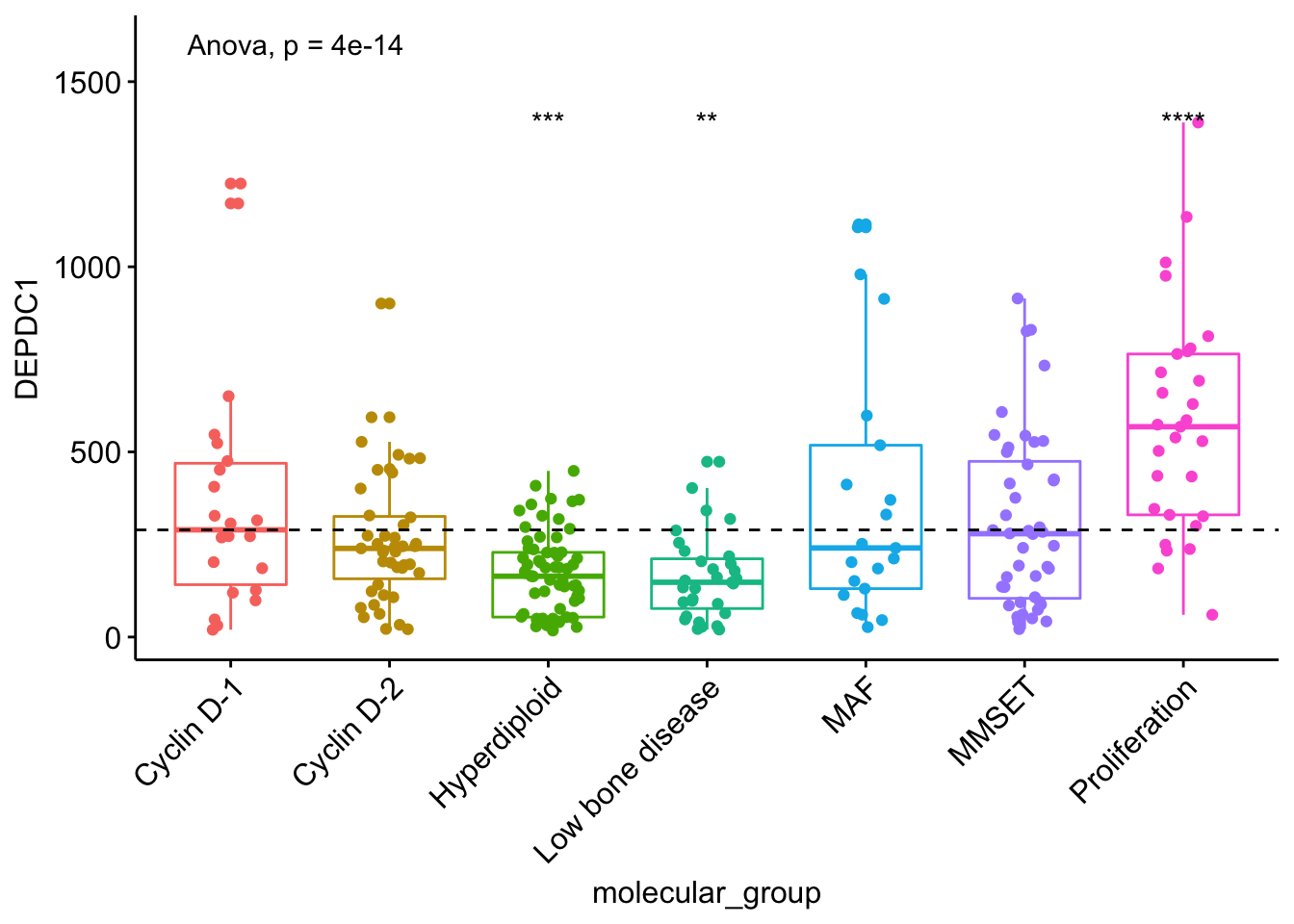
Add p-values and significance levels to ggplots
Multiple grouping variables
- Two independent sample comparisons after grouping the data by another variable:
Perform the test:
compare_means(len ~ supp, data = ToothGrowth,
group.by = "dose")# A tibble: 3 x 9
dose .y. group1 group2 p p.adj p.format p.signif method
1 0.5 len OJ VC 0.023186427 0.04637285 0.023 * Wilcoxon
2 1.0 len OJ VC 0.004030367 0.01209110 0.004 ** Wilcoxon
3 2.0 len OJ VC 1.000000000 1.00000000 1.000 ns Wilcoxon In the example above, for each level of the variable “dose”, we compare the means of the variable “len” in the different groups formed by the grouping variable “supp”.
Visualize (1/2). Create a multi-panel box plots facetted by group (here, “dose”):
# Box plot facetted by "dose"
p <- ggboxplot(ToothGrowth, x = "supp", y = "len",
color = "supp", palette = "jco",
add = "jitter",
facet.by = "dose", short.panel.labs = FALSE)
# Use only p.format as label. Remove method name.
p + stat_compare_means(label = "p.format")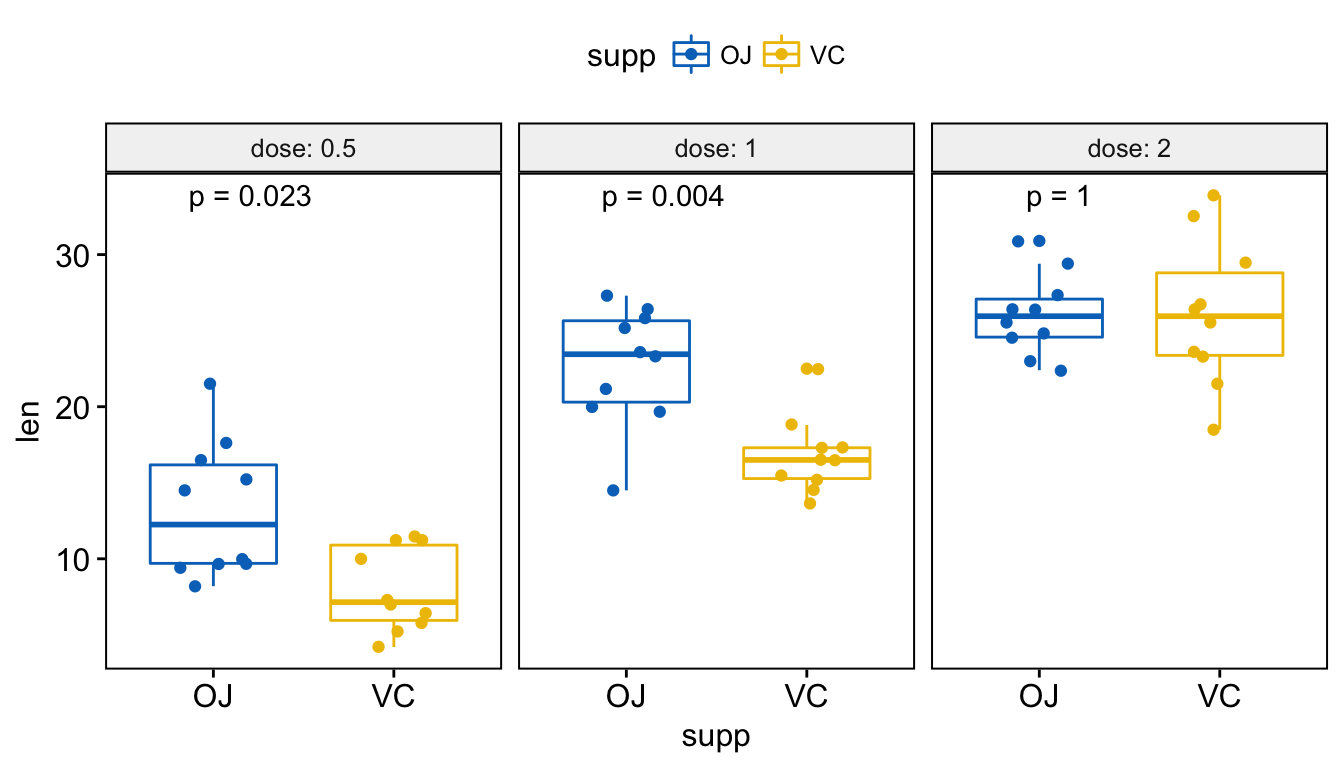
Add p-values and significance levels to ggplots
# Or use significance symbol as label
p + stat_compare_means(label = "p.signif", label.x = 1.5)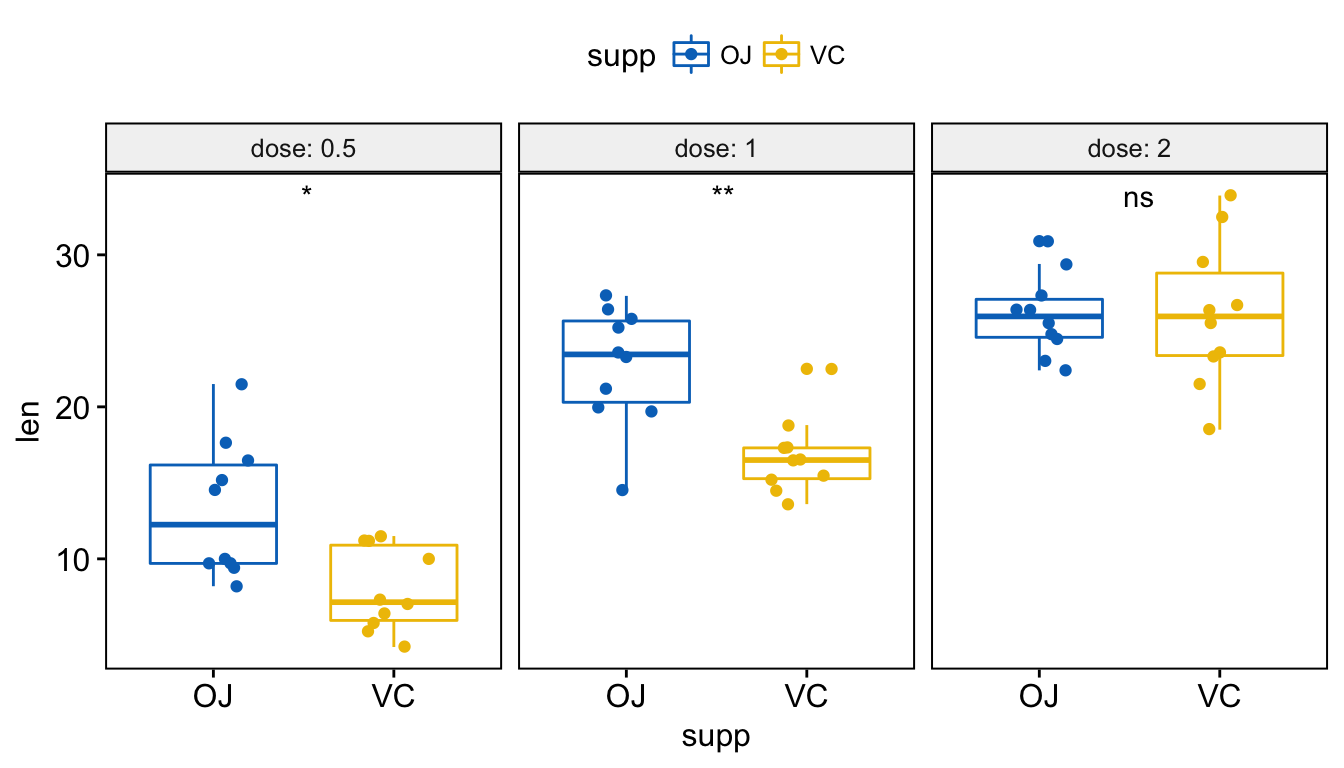
Add p-values and significance levels to ggplots
To hide the ‘ns’ symbol, use the argument hide.ns = TRUE.
Visualize (2/2). Create one single panel with all box plots. Plot y = “len” by x = “dose” and color by “supp”:
p <- ggboxplot(ToothGrowth, x = "dose", y = "len",
color = "supp", palette = "jco",
add = "jitter")
p + stat_compare_means(aes(group = supp))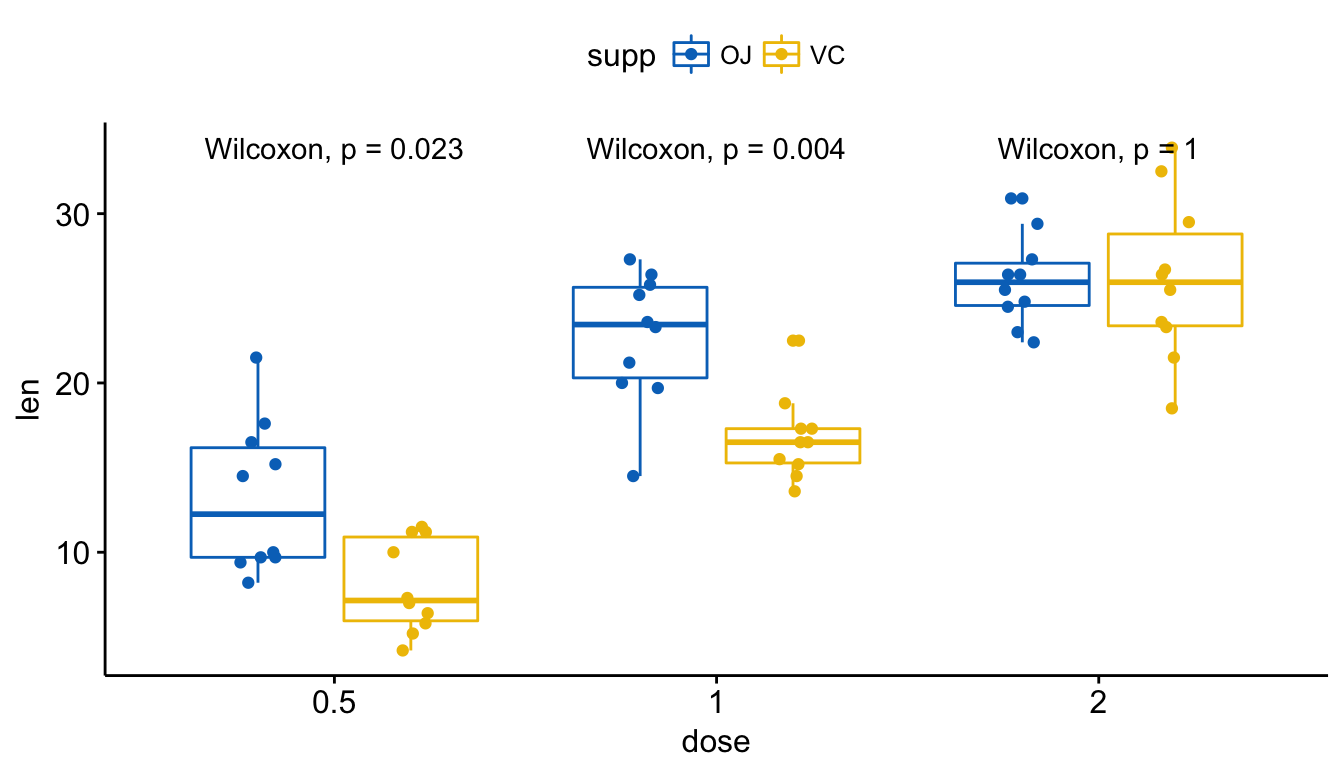
Add p-values and significance levels to ggplots
# Show only p-value
p + stat_compare_means(aes(group = supp), label = "p.format")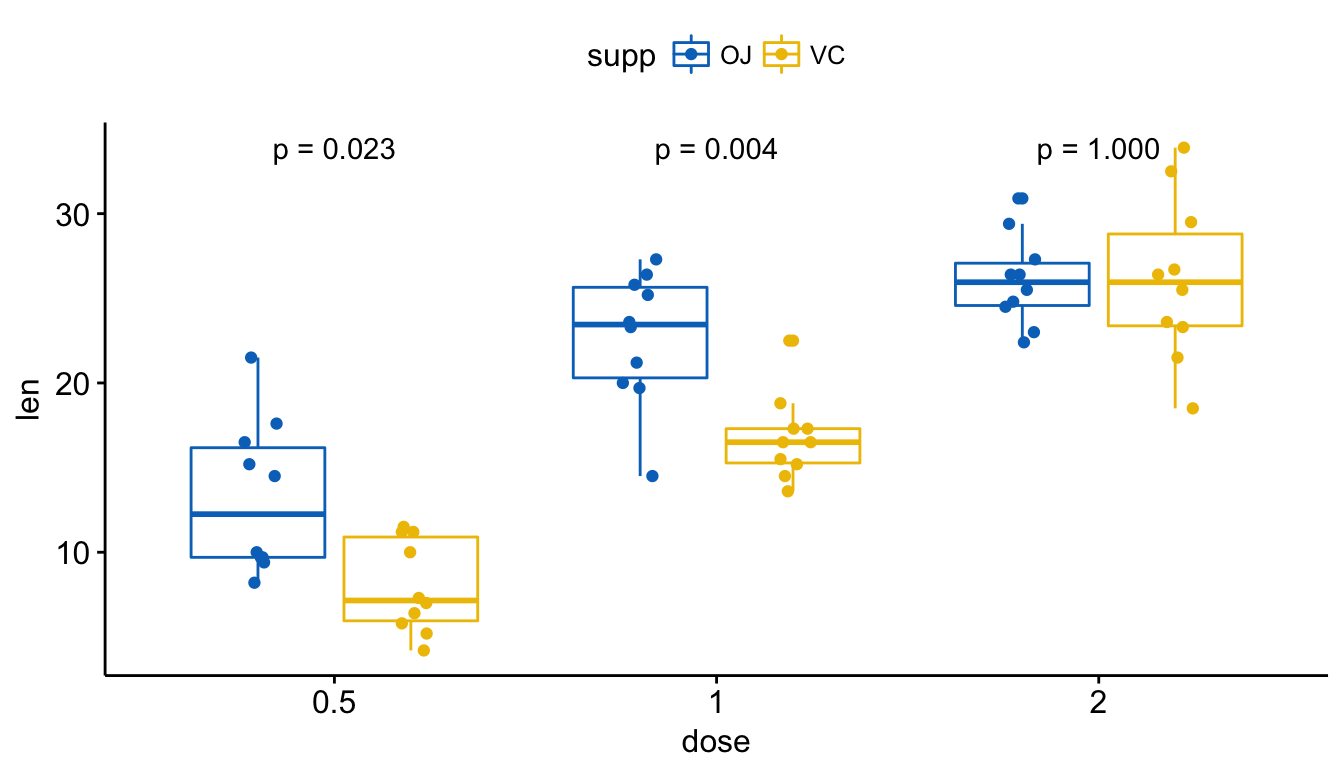
Add p-values and significance levels to ggplots
# Use significance symbol as label
p + stat_compare_means(aes(group = supp), label = "p.signif")
Add p-values and significance levels to ggplots
- Paired sample comparisons after grouping the data by another variable:
Perform the test:
compare_means(len ~ supp, data = ToothGrowth,
group.by = "dose", paired = TRUE)# A tibble: 3 x 9
dose .y. group1 group2 p p.adj p.format p.signif method
1 0.5 len OJ VC 0.03296938 0.06593876 0.033 * Wilcoxon
2 1.0 len OJ VC 0.01905889 0.05717667 0.019 * Wilcoxon
3 2.0 len OJ VC 1.00000000 1.00000000 1.000 ns Wilcoxon Visualize. Create a multi-panel box plots facetted by group (here, “dose”):
# Box plot facetted by "dose"
p <- ggpaired(ToothGrowth, x = "supp", y = "len",
color = "supp", palette = "jco",
line.color = "gray", line.size = 0.4,
facet.by = "dose", short.panel.labs = FALSE)
# Use only p.format as label. Remove method name.
p + stat_compare_means(label = "p.format", paired = TRUE)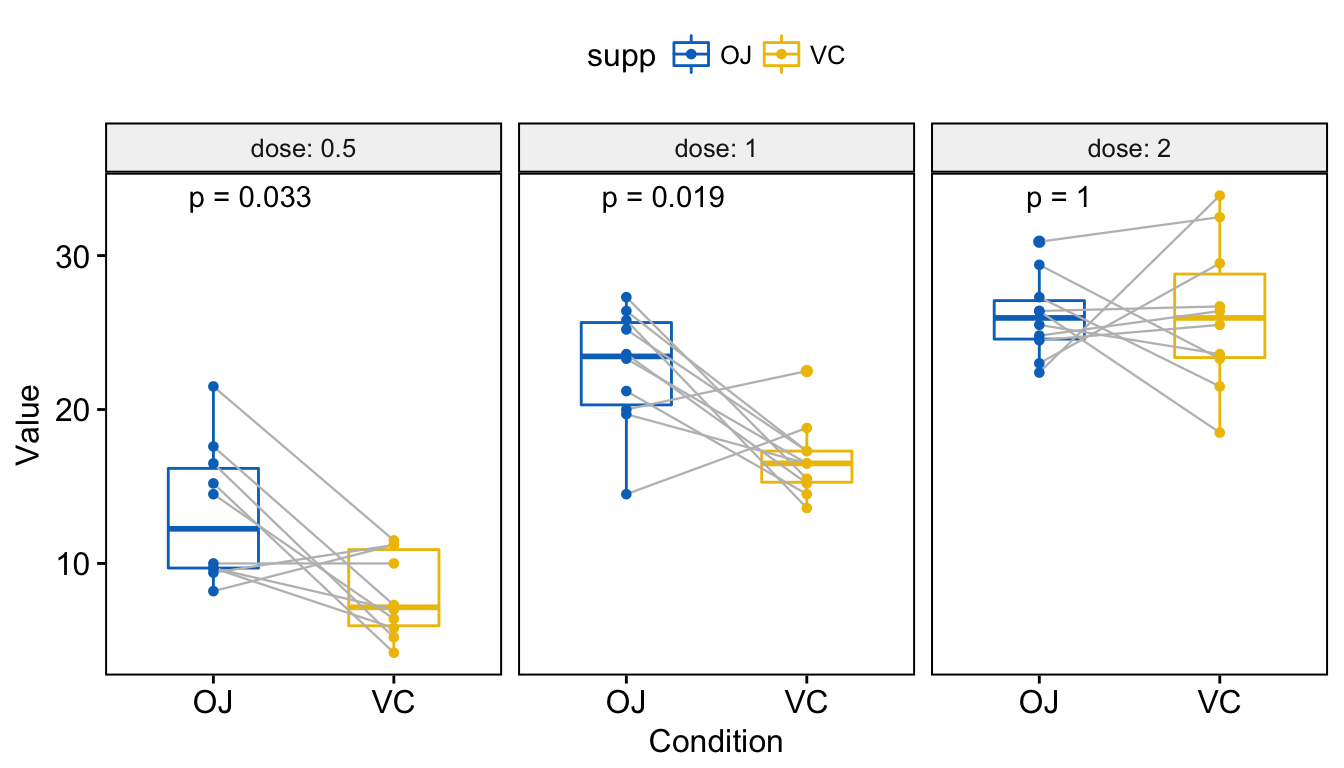
Add p-values and significance levels to ggplots
Other plot types
- Bar and line plots (one grouping variable):
# Bar plot of mean +/-se
ggbarplot(ToothGrowth, x = "dose", y = "len", add = "mean_se")+
stat_compare_means() + # Global p-value
stat_compare_means(ref.group = "0.5", label = "p.signif",
label.y = c(22, 29)) # compare to ref.group
# Line plot of mean +/-se
ggline(ToothGrowth, x = "dose", y = "len", add = "mean_se")+
stat_compare_means() + # Global p-value
stat_compare_means(ref.group = "0.5", label = "p.signif",
label.y = c(22, 29)) 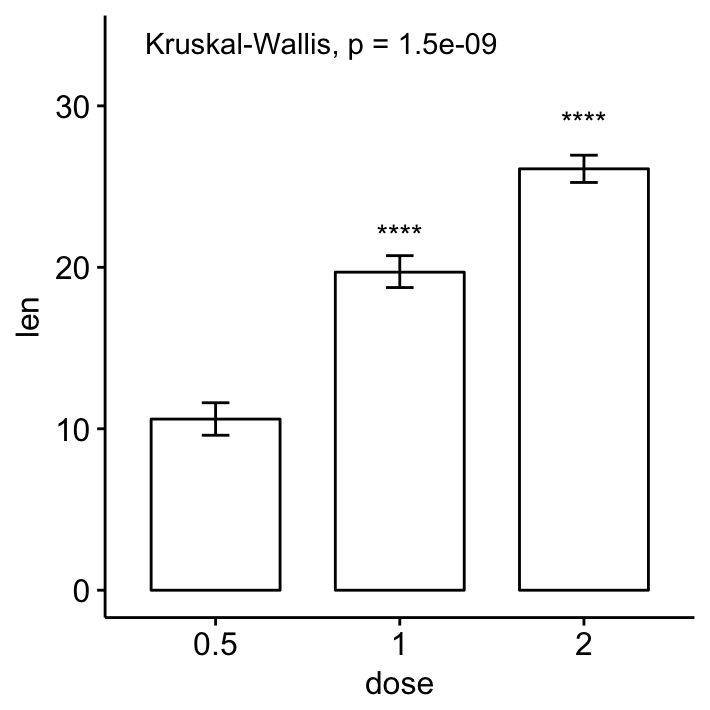
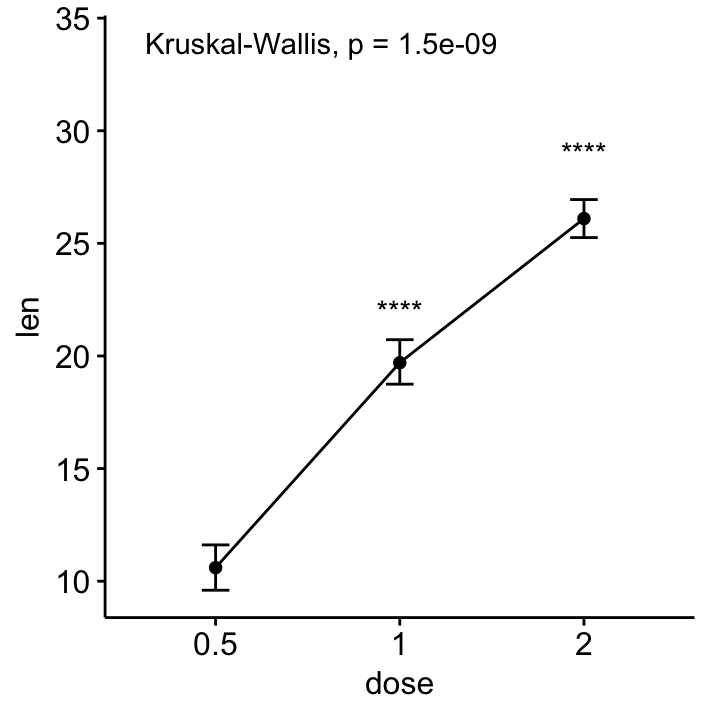
Add p-values and significance levels to ggplots
- Bar and line plots (two grouping variables):
ggbarplot(ToothGrowth, x = "dose", y = "len", add = "mean_se",
color = "supp", palette = "jco",
position = position_dodge(0.8))+
stat_compare_means(aes(group = supp), label = "p.signif", label.y = 29)
ggline(ToothGrowth, x = "dose", y = "len", add = "mean_se",
color = "supp", palette = "jco")+
stat_compare_means(aes(group = supp), label = "p.signif",
label.y = c(16, 25, 29))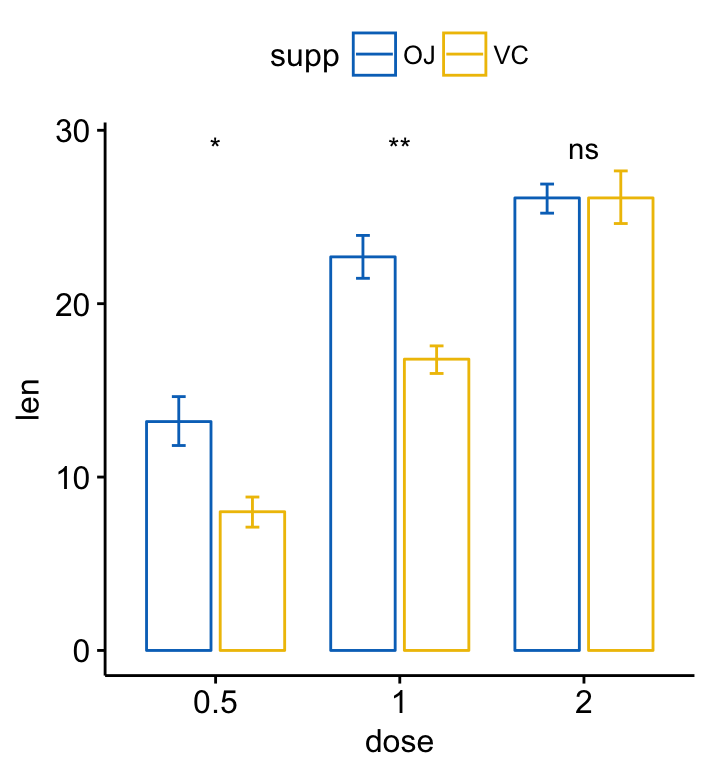
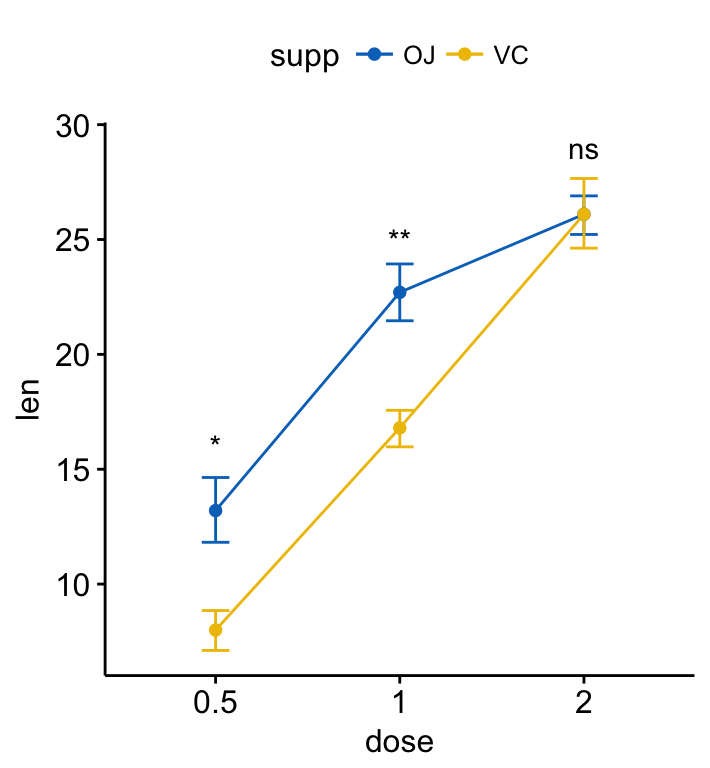
Add p-values and significance levels to ggplots
Infos
This analysis has been performed using R software (ver. 3.3.2) and ggpubr (ver. 0.1.3).